Basic Concept
Dojo is built on a simulation framework that that uses agent-based modelling. This enables dynamic backtesting and simulation of DeFi strategies and smart contracts, for robust risk management pre-deployment.
To make things easier, let's consider an example of a trader trading on UniswapV3, and breakdown how Dojo operates:
Simulation Framework
- Environment Setup: The first step is setting up an environment, which represents a DeFi protocol. In this case Uniswap V3. This environment includes the exact bytecode of the protocol, ensuring an accurate simulation of the protocol’s functionality. The Uniswap environment can have one or more liquidity pools.
- Define Agents: Create agents to interact with the environment. Each agent can represent different roles, such as traders, liquidity providers, or wider market behavior. You’ll need to define a reward function for each agent, which translates the observations from the environment into a measure of the agent's performance.
- Policy Execution: Policies govern how agents act based on observations. Observations provide information on the state of the environment. These obervations are turned into actions via policies. For example, a trading policy might execute trades based on current price information from Uniswap V3. These policies can be as simple or complex as needed, depending on the strategy.
- Action Processing: Actions taken by agents are executed within the environment. This can be imagined as Uniswap processing the trader's trade on the blockchain. The environment updates with new observations reflecting the results of these actions, and agents receive feedback on their performance.
Performance Measurement
Static Policy
For static policies, the agent's reward function evaluates performance based on the policy's actions throughout the simulation. In this case, the reward function does not influence the agent's actions within the simulation.
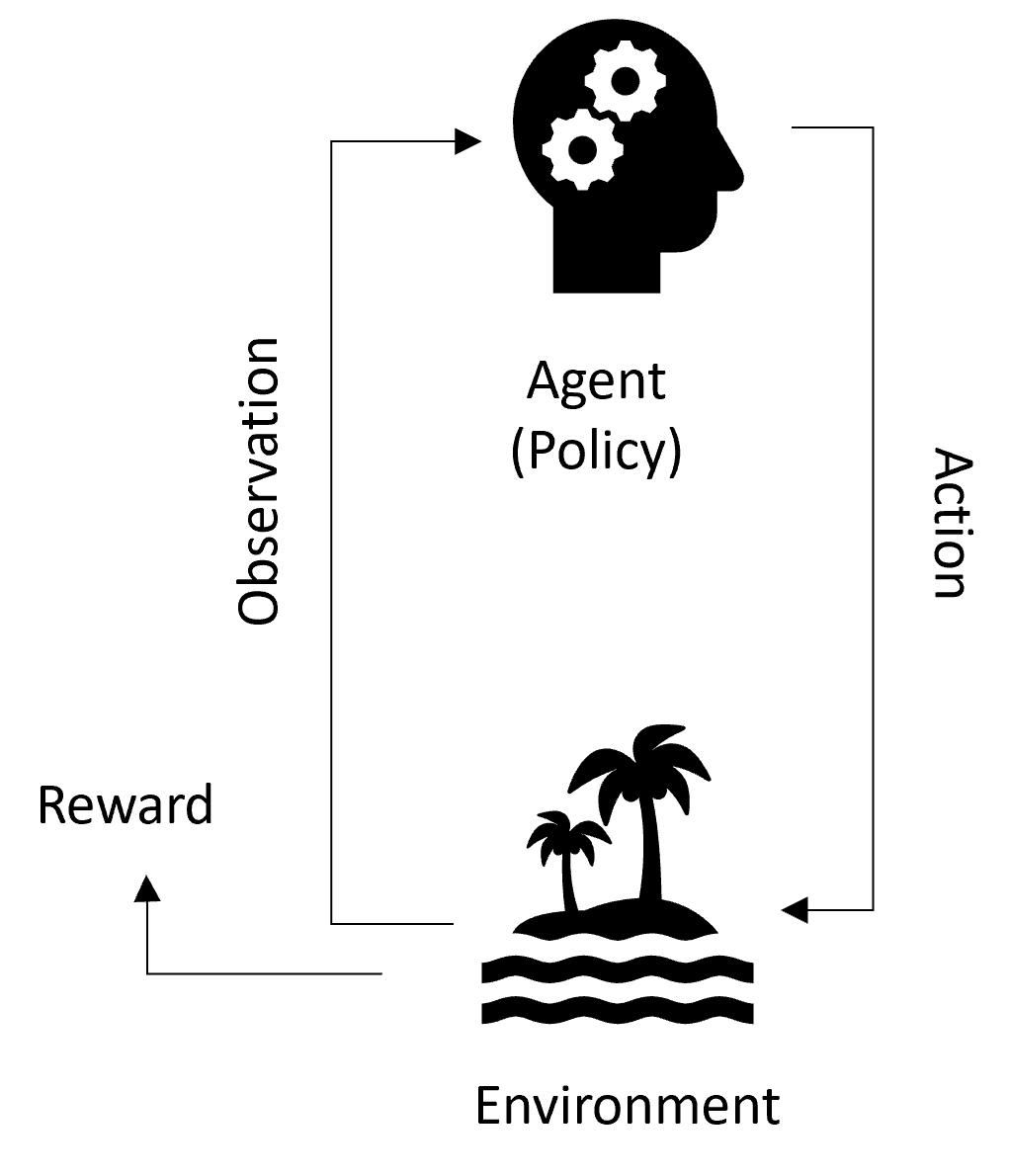
Terminology
Environments
Environments represent DeFi protocols (e.g. Uniswap V3 or AAVE).
Environments represent the setting in which an agent interacts and possibly learns. At every simulation step (every block on the blockchain), the environment emits both an observation and rewards generated by the agents in the simulation. The observation provides information on the state of the environment at the current simulation block.
The agents' policies process the observation and rewards to take a sequence of actions. The actions are executed inside the environment. In practice this means Dojo makes the appropriate smart contract call to our local fork of the DeFi protocol, and emits new observations, i.e. the updated state of the chain, back to the simulation.
See here for more details.
Agents
Agents represent the state of the actors interacting with the environment (e.g. traders).
The environment has reference to all agents, each of which keeps track of their own cryptocurrency quantities. They also implement their own reward function for metric tracking, and, optionally, policy training.
Agents are NOT responsible for making decisions on how to act in the environment.
See here for more details.
Policies
Policies determine the behavior of the agents.
This is where you can get creative by implementing your own policy for interacting with the environment! For example, a basic policy could be the moving average trading strategy.
At every simulation step (i.e., every block), the policy receives an observation from the environment, with which it generates a sequence of actions to pass back. Optionally, it also receives a reward which can be used to train or fit a model contained within it.
See here for more details.