Simulation Loop
The simulation loop in dojo brings everything together through an iterative process on a per block basis.
At each step the environment emits an observation and the agents' rewards. These are processed by the policy which generates a sequence of actions. This is passed to the environment, which emits a new observation reflecting the new state of the protocol, and the agents' rewards for taking those actions.
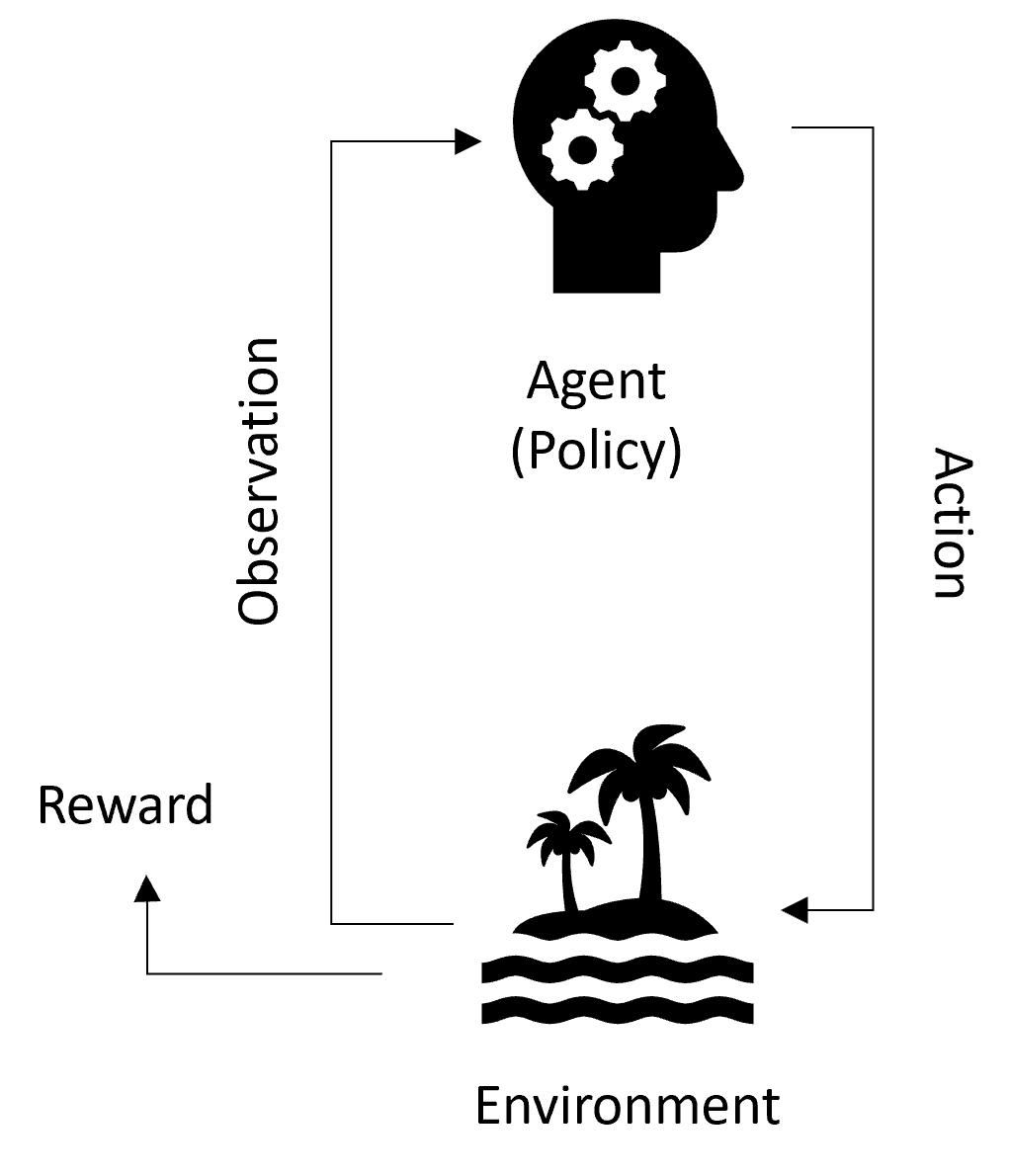
Basic Pattern
This is the basic pattern of the simulation loop:
- Firstly, the environment emits an initial observation to the agent, which represents the state of the environment.
- Then the agent takes in the observations and makes decisions based on its policy. It also computes its reward based on observations.
- If you are testing your strategy, this reward is simply a way of measuring your strategy performance.
- The environment executes the actions and moves forward in time to the next block.
- The simulation loop keeps repeating this cycle until it reaches the end block.
If you want a reminder on some of the concepts here, take a longer peek at the environment, the agent or the policy as you see fit.
Example
pools = ["USDC/WETH-0.05"]
start_time = "2024-12-06 13:00:00"
chain = Chain.ETHEREUM
block_range = (
time_to_block(start_time, chain),
time_to_block(start_time, chain) + num_sim_blocks,
)
# block_range = 21303933, 21354333
market_agent = HistoricReplayAgent(
chain=chain, pools=pools, block_range=block_range
)
# Agents
trader_agent = TotalWealthAgent(
initial_portfolio={
"ETH": Decimal(100),
"USDC": Decimal(10_000),
"WETH": Decimal(100),
},
name="TraderAgent",
unit_token="USDC",
policy=MovingAveragePolicy(
pool="USDC/WETH-0.05", short_window=25, long_window=100
),
)
lp_agent = TotalWealthAgent(
initial_portfolio={"USDC": Decimal(10_000), "WETH": Decimal(100)},
name="LPAgent",
unit_token="USDC",
policy=PassiveConcentratedLP(lower_price_bound=0.95, upper_price_bound=1.05),
)
# Simulation environment (Uniswap V3)
env = UniswapV3Env(
chain=chain,
block_range=block_range,
agents=[market_agent, trader_agent, lp_agent],
# agents=[market_agent],
pools=pools,
backend_type="local",
)
# SNIPPET 2 START
backtest_run(
env,
dashboard_server_port=dashboard_server_port,
auto_close=auto_close,
simulation_status_bar=simulation_status_bar,
output_file="example_backtest.db",
simulation_title="Example backtest",
simulation_description="Example backtest. One LP agent, one trader agent.",
)
# SNIPPET 2 ENDThis is a visualization of the above simulation:

Saving data
One way to store data is through the dashboard. The dashboard allows you to save all data in JSON format on a per block basis. You can load it into an empty dashboard later, or read the JSON for further processing. You can also turn a db file produced by your simulation directly into JSON format by using `dojo.external_data_providers.exports.json_convertor. Consult the documentation for more details.